Duplikate entfernen im Power Query Editor funktioniert nicht
 Rainer Knappe
Rainer KnappeEins gleich vorweg: der Titel müsste eigentlich heißen: „… funktioniert vermeintlich nicht“, denn das Entfernen von Duplikaten in Power Query funktioniert sehr wohl. Man kann nur leicht in eine bestimmte Falle tappen und um diese geht es hier.
Vielleicht kommt Euch diese Situation bekannt vor:
Ihr habt eine Faktentabelle und eine Dimensionstabelle und wollt in der Modell-Ansicht von Power BI eine Beziehung zwischen den Tabellen herstellen.
Ihr zieht per Drag and Drop eine Spalte der einen Tabelle über die entsprechende Spalte der anderen Tabelle und… bekommt diese Warnmeldung:

„Diese Beziehung hat eine Kardinalität von m:n. Diese darf nur verwendet werden, wenn zu erwarten ist, dass keine Spalte (…) eindeutige Werte enthält, und wenn das erheblich abweichende Verhalten von m:n-Beziehungen bekannt ist“.
Die Warnmeldung kommt deshalb, da in aller Regel Werte in der Faktentabelle zwar mehrfach vorkommen werden und dürfen, in einer Dimensionstabelle (oder auch Lookup-Tabelle genannt) aber eindeutig sein sollten, also nur genau ein mal vorkommen sollten. Die Beziehung sollte also nicht m:n sein, sondern 1:n. Ausnahmen von dieser Regel gibt es zwar, das sollte aber selten vorkommen und möglichst vermieden werden.
Ich hatte genau diese Phänomen kürzlich. Eine Dimensionstabelle, die so aus dem ERP-System kam, sollte eigentlich eindeutige Werte enthalten.
Da die Tabelle aber mehrere Hunderttausend Datensätze enthielt, war ich nicht sehr überrascht, dass wohl doch Duplikate vorhanden waren. Das kommt in den besten Familien vor.
Meine Idee war nun, im Power Query Editor die Funktion „Duplikate entfernen“ zu verwenden (Rechtsklick auf die Spaltenüberschrift, dann aus dem Kontextmenü „Duplikate entfernen“ auswählen).
Gedacht, getan.
Dann unternahm ich den zweiten Versuch, die Beziehung zur Faktentabelle herzustellen. Ergebnis: wieder bekam ich den Hinweis, dass die Beziehung eine Kardinalität von m:n hat.
Das darf aber doch nicht sein, wenn ich alle Duplikate entfernt habe? Darf es auch nicht.
Ursache: Groß- und Kleinschreibung wird in Power Query unterschieden
Die Ursache war bei mir, und so wird es bei Euch auch sein, dass Power Query die Groß- und Kleinschreibung in Tabellenwerten unterscheidet, also Case-Sensitive ist.
Machen wir ein einfaches Beispiel:
Meine Dimensionstabelle enthält Artikel-Nummern und die Preise der Artikel:

In meiner (sehr einfachen) Faktentabelle habe ich Kundennamen und die Artikel-Nummern, die die Kunden gekauft haben.
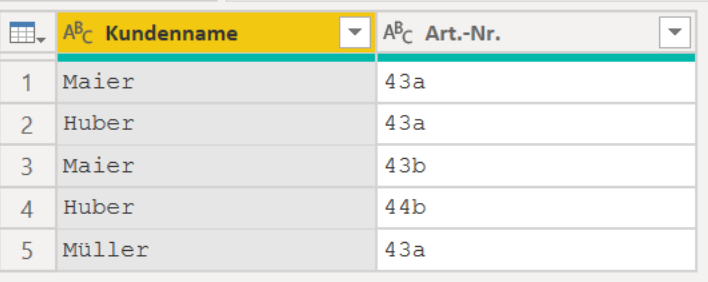
In der Faktentabelle habe ich keine einzigartigen Werte. Der Kunde Maier hat z.B. mehrere Artikel gekauft und der Artikel 43a wurde mehrfach verkauft. So sollte es in der realen Welt im Normalfall sein.
Das „Problem“ mit der Groß- und Kleinschreibung
Was passiert nun, wenn ich in der Dimensionstabelle die Spalte Art.-Nr. anklicke und „Duplikate entfernen“ auswähle? Genau: es passiert rein gar nichts!
Der Grund ist, dass es hier keine Duplikate gibt. Der Artikel 43a ist ein anderer als der Artikel 43A.
Womöglich gibt es im Unternehmen die Konvention, dass Artikelnummern immer ein Kleinbuchstabe angehängt wird (der z.B. die Farbe angibt). Hier hat ein Mitarbeiter beim Erfassen des Artikels 43A einfach einen Fehler gemacht. Vielleicht sind es aber auch wirklich unterschiedliche Artikel!
Die Lösung (mit Vorsicht anzuwenden): Nivellieren der Groß- und Kleinschreibung
Mit Nivellieren meine ich hier, die groß- und kleingeschriebenen Werte auf den selben Wert – das selbe Niveau – zu bringen. Also entweder alles groß oder alles klein zu schreiben.
Nehmen wir an, es gibt im Unternehmen tatsächlich besagte Regel, dass die Farbe in der Artikelnummer immer mit einem Kleinbuchstaben anzugeben ist. Dann könnte ich folgendes tun:
Rechtsklick auf die Spalte Art.-Nr., dann im Kontextmenü „Transformieren“ ausführen und dann „kleinbuchstaben“ (sic!) wählen.
Wenn ich nun „Duplikate entfernen“ nochmals ausführe, werden die Duplikate wie gewünscht gelöscht.
Aber Vorsicht: wenn ich nun einen Artikel 43a mit einem Preis von 5 Euro habe und einen Artikel 43a, der 10 Euro kostet (und in der Tabelle weiter unten steht), bleibt nur der Artikel mit dem Preis von 5 Euro übrig. Man sollte hier also wissen, was man tut (das empfiehlt sich ohnehin immer 😉 ). In meinem Fall konnte ich die Werte der Dimensionstabelle mit gutem Gewissen nivellieren.
Seid Ihr auf dieses Problem auch schon mal gestoßen? Wie geht Ihr dann vor?
 Rainer Knappe
Rainer Knappe
Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!