Umzug von lokalem Ordner in SharePoint-Ordner
 Rainer Knappe
Rainer KnappeWie kann man Quell-Dateien von einem lokalen Ordner nachträglich in einen SharePoint-Ordner umziehen?
Auf Dateien auf einer lokalen Maschine kann man über ein Data Gateway zugreifen. Wie das funktioniert, habe ich hier beschrieben. Entscheidet man sich nachträglich dazu, die Dateien in einen SharePoint-Ordner zu verschieben, müssen die Verbindungen im PowerBI-Bericht von der lokalen Quelle auf den SharePoint-Ordner umgebogen werden.
Am besten ist es natürlich, die Entscheidung, wo die Quell-Daten liegen, von vorne herein sinnvoll zu planen. Aber das Leben ist bekanntlich nicht immer ein Ponyhof.
Wie immer, führen mehrere Wege zum Ziel. Ich beschreibe hier, wie ich es für mich gelöst habe. Schreibt gerne in die Kommentare, wenn Ihr alternative oder einfachere Methoden kennt.
Beispiel – Die Ausgangslage
Ich habe einen Power BI – Bericht Umzug.pbix. Dieser basiert auf einer csv-Datei namens test.csv. Diese csv-Datei liegt auf meiner Festplatte im Verzeichnis temp. Der komplette Pfad lautet also c:\temp\test.csv.
Im erweiterten Editor sieht der M-Code wie folgt aus:
let
Quelle = Csv.Document(File.Contents("C:\temp\test.csv"),[Delimiter=";", Columns=3, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Höher gestufte Header" = Table.PromoteHeaders(Quelle, [PromoteAllScalars=true]),
#"Geänderter Typ" = Table.TransformColumnTypes(#"Höher gestufte Header",{{"Datum", type date}, {"Artikel", type text}, {"Preis", type number}})
in
#"Geänderter Typ"Nun könnte man auf die Idee kommen, im M-Code einfach den Text für „Quelle“ auszutauschen. Das ist zwar prinzipiell auch richtig, ganz so trivial ist es aber nicht.
Anleitung für den Umzug
Zunächst laden wir die Datei test.csv in einen SharePoint-Ordner, auf den wir natürlich Lese- und Schreibberechtigungen haben müssen. Ich habe für das Beispiel unter „Dokumente“ einen Ordner „PowerBITransfer“ angelegt.
Nun kommt bereits der vielleicht kniffligste Teil, wenn man es nicht weiß.
Wir kopieren nun den Pfad zum SharePoint, in dem unser Ordner liegt, aus der Browser-Zeile in die Zwischenablage.
Hier kopieren wir nur den übergeordneten Bereich inklusive dem abschließenden /

Wir wechseln nun über „Daten transformieren“ in den PowerQuery-Editor unseres Projekt.
Im PowerQuery-Editor legen wir über die Schaltfläche „Neue Quelle“ eine neue Quelle an. Wenn wir im sich öffnenden Dialog im Suchfeld „SharePoint“ eingeben, wird uns „SharePoint-Ordner“ angeboten. Hier klicken wir auf „Verbinden“.
Es öffnet sich ein Dialog, in dem wir die zuvor kopierte URL bei Website-URL einfügen. Dann klicken wir auf „OK“.
Im nächsten Dialog-Fenster wählen wir die Ebene aus, in der sich unser Ordner befindet.
Nun müssen wir noch auf „Microsoft-Konto“ klicken und unsere Zugangsdaten für das Microsoft-Konto angeben, mit dem auf den SharePoint-Ordner zugegriffen werden soll. Dann klicken wir auf „Verbinden“.
Es öffnet sich die Vorschau mit allen Elementen, auf die wir in diesem SharePoint zugriff haben. Wir klicken hier auf „Daten transformieren“.
Nun kommt der zweite trickreiche Schritt, damit wir den richtigen Ordner, hier „PowerBITransfer“, finden.
Ganz rechts in der Tabelle findet sich die Spalte „Folder Path“.
In der Spalten-Überschrift klicken auf den kleinen Button rechts und wählen im Dialog „Textfilter“ und dann „Enthält…“.
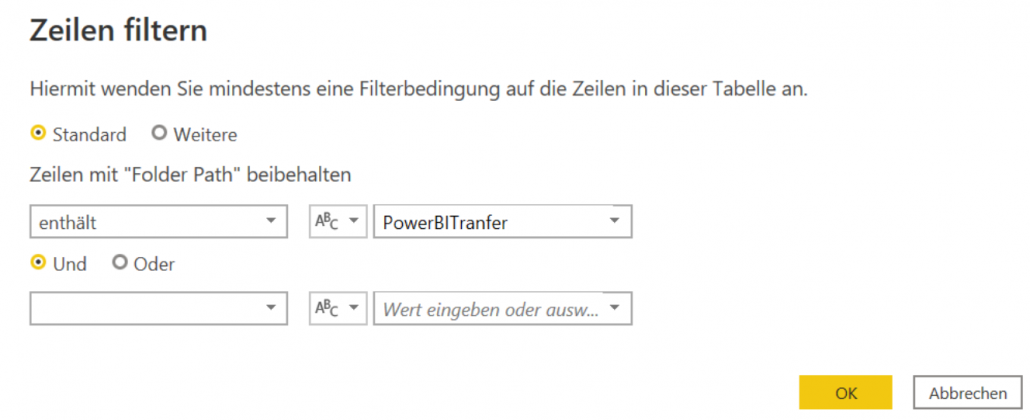
In diesem Dialog geben wir als Suchstring unseren Ordnernamen „PowerBITransfer“ an. Dann klicken wir „Ok“.
Die Anzahl an Zeilen in der Tabelle hat sich nun drastisch reduziert. Angezeigt wird uns nun jede Datei, die sich im SharePoint-Ordner „PowerBITransfer“ befindet. In meinem Fall ist das nur die „test.csv“.
Wir wechseln nun auf die erste Spalte der Tabelle namens „Content“.
Hinweis: wenn wir in unserem Ordner mehrere Dateien mit derselben Struktur liegen haben, können wir über das Icon mit dem Doppelpfeil nach unten diese Dateien hier gleich kombinieren.
In meinem Beispiel mit nur einer Datei klicke ich auf den Link „Binary“ in der Spalte „Content“.
Es wird nun eine zweite Abfrage mit den entsprechenden angewendeten Schritten erstellt.
Die Abfrage heißt zunächst „Abfrage1“. Ich ändere den Namen ab in „PowerQueryAbfrage“.
PowerQuery hat mir hier gleich zwei Schritte eingefügt: „Höher gestufter Header“ und „Geänderter Typ“. Diese Schritte lösche ich aus der Liste der angewendeten Schritte, da ich diese bereits in der ursprünglichen Abfrage habe und diese somit doppelt vorhanden wären. Hier würde es im weiteren Verlauf krachen.
Nun speichere ich das Projekt zwischen und lasse die Abfragen dabei aktualisieren.
Die Quelle in der ursprünglichen Abfrage austauschen
Jetzt kommt der letzte, entscheidende Schritt. Und diesen Schritt finde ich sehr elegant:
Wir gehen mit der rechten Maustaste auf unsere Ursprüngliche Abfrage. In meinem Fall heißt diese „Test“.
Im Kontextmenü wählen wir „Erweiterter Editor“ und gelangen somit in den M-Editor.
In der ersten Zeile nach „let“ steht hier noch „Quelle = Csv.Document(File.Contents(„c:\temp\test.csv…“
In dieser Zeile löschen wir alles, was zwischen dem = und dem Komma am Ende steht (das Komma muss bleiben!) raus und ersetzen den String einfach mit dem Namen unserer neuen Abfrage. Hier schlägt uns IntelliSense sogar den Namen der Abfrage vor.

IntelliSense schlägt uns unsere neue Abfrage vor
Der M-Quellcode sieht nun so aus:
let
Quelle = PowerQueryAbfrage,
#"Höher gestufte Header" = Table.PromoteHeaders(Quelle, [PromoteAllScalars=true]),
#"Geänderter Typ" = Table.TransformColumnTypes(#"Höher gestufte Header",{{"Datum", type date}, {"Artikel", type text}, {"Preis", type number}}),
#"Hinzugefügte benutzerdefinierte Spalte" = Table.AddColumn(#"Geänderter Typ", "doppelter Preis ", each [Preis]*2),
#"Geänderter Typ1" = Table.TransformColumnTypes(#"Hinzugefügte benutzerdefinierte Spalte",{{"doppelter Preis ", type number}})
in
#"Geänderter Typ1"Nun klicken wir noch auf „Fertig“ und – Voila – wir haben ab sofort unseren SharePoint-Ordner als Quellordner.
Wir können das Projekt nun im Power BI – Service veröffentlichen.
Damit das Dataset jedoch auch automatisiert oder händisch aktualisiert werden kann, muss in den Einstellungen des Datasets noch ein Microsoft-Konto mit den entsprechenden Berechtigungen auf den SharePoint-Ordner eingetragen werden.
Es empfiehlt sich hier, ein generisches Konto zu verwenden – denn wenn wir die Firma irgendwann mal verlassen (und sei es spätestens mit der Rente), sollen ja nicht alle Konnektoren umgeschrieben werden müssen.
Habt Ihr Vorschläge für eine Vereinfachung des Vorgehens? Das würde mich wirklich sehr interessieren.
Schreibt Eure Anmerkungen gerne in die Kommentare!
Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!